You’re monitoring 300 machines, and one is about to fail. Your facility team jumps into action, scrambling to fix it — only to realize later that another machine, far more critical to your operations, is also on the brink of failure.
For many teams, this scenario is all too common. Without a clear strategy to prioritize risk, maintenance efforts are scattered, leaving critical machines vulnerable to unplanned downtime, lost productivity, and costly repairs.
Predictive maintenance tools promise to catch failures before they happen, but even the smartest technology can’t succeed without direction. If you don’t know which machines are critical to your operations or lack the processes to manage and act on that knowledge, you’re just guessing.
The solution starts with knowing how to identify risk, integrate insights across work management and reliability systems, and act on them effectively. Criticality analysis is the first step to getting this right. Then, when paired with the right technology, you can turn your insights into action.
What is Asset Criticality and Why Does It Matter?
Not all machines are equally important in the workplace. Some assets are the backbone of operations — when they fail, production stops, costs spiral, and schedules derail. Others are less critical, and you can afford to postpone repairs. The challenge lies in determining which machines matter most and prioritizing resources accordingly.
While many organizations think they know their critical assets, this knowledge often relies on intuition rather than a structured process. Teams may believe they understand which machines are most important but lack a formal list or scoring system to back up these assumptions.
Without a standardized approach to asset prioritization, maintenance teams risk falling into common traps:
- Wasting resources on unnecessary tasks for low-priority equipment
- Missing critical failures that lead to costly downtime
- Reacting to emergencies instead of proactively managing equipment health
A formal criticality analysis provides a clear, data-driven framework that removes guesswork and makes sure maintenance efforts are directed where they’re needed most. At its core, it involves asking key questions to uncover which assets carry the highest risks. Questions like:
- What happens if this machine fails?
- How frequently does this asset fail, and what are the repair costs?
- Does failure pose safety risks or regulatory compliance issues?
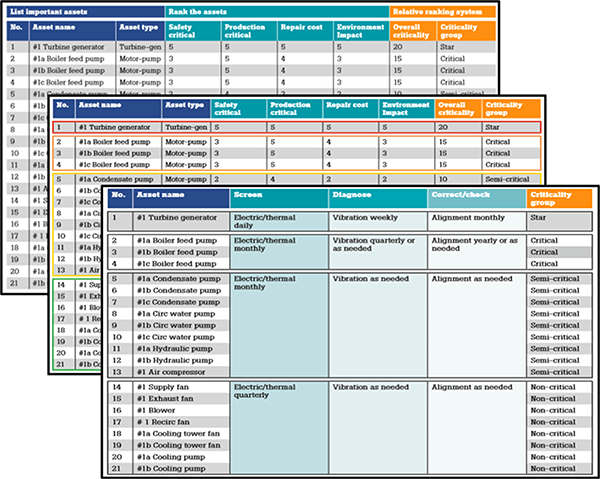
Structured workshops, completed by stakeholders from different teams, are often the best way to answer these questions. With input from maintenance, production, and engineering teams, each asset can be evaluated based on the questions listed above, and additional criteria that reveal its true impact on operations:
- Safety: Could failure result in injury, environmental harm, or regulatory penalties?
- Production impact: How much revenue is lost for every hour — or even minute — of downtime?
- Failure frequency: Are recurring issues eating up time and resources?
- Repair costs: Which failures are the most expensive to fix?
- Spare availability: How quickly can repairs be made with the parts on hand?
- Quality implications: Could failure lead to compromised product output or costly rework?
The outcome isn’t a vague list of “high,” “medium,” or “low” priorities. Instead, machines are force-ranked based on their relative risk and impact, receiving precise scores that show exactly where attention should go first. (If your organization has a well-implemented computerized maintenance management system (CMMS) and a solid work management process, some of this data might already exist and can be pulled directly into the analysis. But even then, it’s the scoring system that turns raw data into actionable insights.)
Take this example: one machine might suffer a catastrophic failure that costs $50,000 to fix, while another might experience eight smaller failures that add up to $10,000. At first glance, both might seem equally important — but a detailed criticality analysis reveals that while the smaller failures don’t take as long to fix, they lead to a greater risk of decreased product quality. Seeing the full picture ensures that resources are directed where they’ll make the biggest difference.
Ranking your critical machines is a big win, but it’s just the beginning. The next step is figuring out how they fail and why. That’s where Failure Mode and Effects Analysis (FMEA) comes in. Think of it as the tool that helps you move from identifying risks to actually planning for them.
How FMEA Builds on Criticality Analysis
FMEA takes the insights from criticality analysis and pushes them further. It examines each critical asset, breaking it down into its core components to answer fundamental questions:
- How does this asset fail? Is it bearing misalignment, seal leaks, or excessive vibration?
- Why does it fail? Could it be due to improper installation, normal wear and tear, or environmental factors?
- What happens when it fails? Does it lead to reduced performance, production delays, or even catastrophic damage?
This deeper analysis helps transform understanding into actionable plans. By identifying specific failure modes, teams can focus their efforts where it matters most. For example, they can prioritize high-impact corrective actions or adopt a deliberate run-to-failure strategy for components where failure is manageable. When failure is inevitable, FMEA ensures that spares and repair resources are ready to minimize downtime.
FMEA also helps teams plan strategically, scheduling downtime to minimize disruptions and targeting preventive maintenance where it truly counts. Beyond that, it tackles recurring “bad actors” — those chronic failures that drain resources and impact cash flow — by addressing their root causes.
Keep in mind that identifying failure modes requires a shift in mindset. Reliability engineering shows us that failure isn’t just about catastrophic breakdowns; it includes any unwanted event, like a pump delivering less flow than required or a motor consuming more energy than expected. These smaller disruptions often go unnoticed but accumulate into significant productivity losses over time. Recognizing these signs early enables teams to act before small inefficiencies snowball into major operational setbacks.
But even the best strategies need a way to turn insights into action. Once you’ve pinpointed the equipment that matters most and gained a clear understanding of how and why they might fail, the challenge is knowing exactly when to act. That’s where tools like Azima DLI come in, pairing strategy with cutting-edge diagnostics to take proactive maintenance to the next level.
How Azima Delivers Early Warnings You Can Act On
Azima DLI does not offer just another monitoring solution. The company’s diagnostic system is designed to answer the critical question: how do you move from understanding risks to preventing failures? By analyzing live data and comparing it to machine-specific benchmarks, Azima doesn’t just tell you something is wrong; it pinpoints exactly what’s wrong, why it’s happening, and when it requires attention.
This capability becomes even more powerful when combined with the groundwork you’ve already laid through asset criticality analysis and FMEA. For instance, if a pump has been identified as critical and its seal recognized as a high-risk component, Azima will monitor key parameters — such as pressure fluctuations or temperature changes — to detect subtle warning signs that could otherwise go unnoticed. Here’s how it works:
- Tailored Insights Through Machine-Specific Baselines
Azima continuously analyzes critical machine inputs — such as vibration patterns, temperature changes, and performance trends — to identify subtle anomalies. These signals are compared against statistical baselines by Azima’s diagnostic engine, which draws from a data lake of over 100 trillion data points spanning 50 machinery component types. This vast repository enables the system to trace information from a machine’s nameplate, model, and serial number to its real-world performance data, creating diagnostics grounded in machine-specific context.This machine-specific precision ensures that insights are reliable, accurate, and specific to your operations, allowing Azima artificial intelligence (AI) algorithms to recognize even the earliest signs of failure — often weeks or months before a breakdown occurs.Click here to read how Azima prevented three asset failures at Standard Steel, saving an entire production line within a month after setup.Through Azima’s user-friendly portal, these insights are transformed into actionable recommendations, enabling teams to address failures proactively.
- Turning Insights Into Action
While the diagnostics by itself are already impressive, what sets Azima apart is its focus on prioritization. As we’ve established, not every piece of equipment or fault requires immediate attention, and Azima’s system ranks issues by severity and impact.

This allows maintenance teams to focus their resources where they’re needed most — addressing high-risk faults before they escalate while avoiding unnecessary interventions for minor anomalies so that maintenance remains both proactive and hyper-targeted.
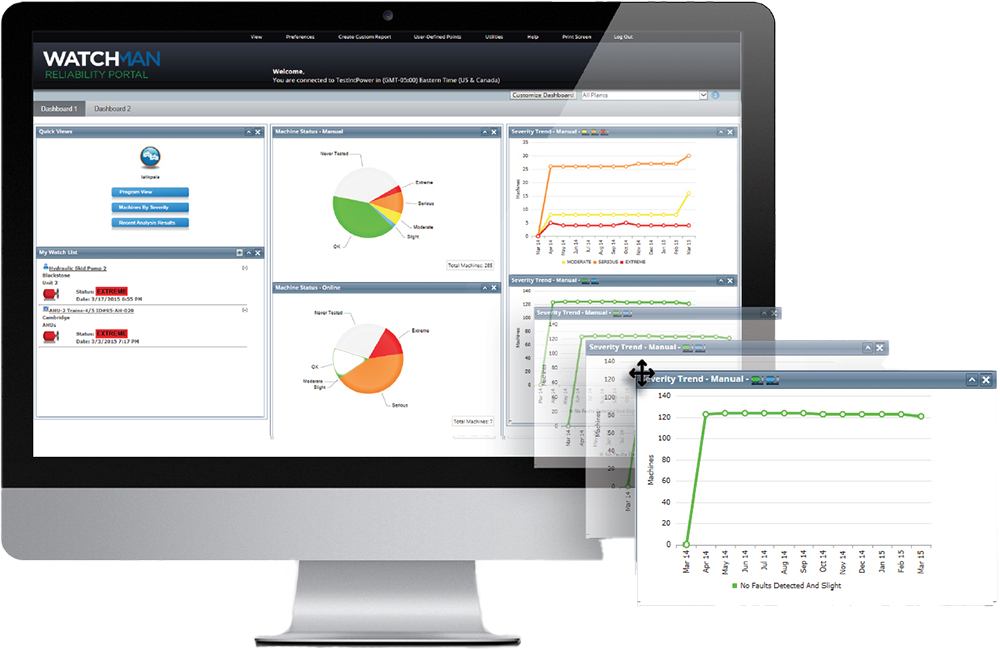
- Tying Risk Analysis to Real-Time Solution
Rather than serving as a mere “check engine light,” Azima’s diagnostics provide specific, actionable recommendations tailored to the failure mode and asset in question. When a seal failure is flagged in a critical pump, for instance, the system can also identify the root cause, whether it’s misalignment, excessive wear, or environmental conditions.This level of detail helps teams plan the exact corrective action needed, minimizing both downtime and guesswork, moving from a reactionary, firefighting mode to one that is more predictive and strategic.Diagnostics are also backed by a team of experienced vibration analysts who review the data alongside the automated system. This human oversight ensures that every recommendation is grounded in both AI precision and expert validation.
- Integrating Seamlessly With Your Existing Data Collection and Workflow
What makes this process seamless is Azima’s ability to integrate with existing workflows. Whether the data comes from its own wireless vibration sensors such as the Accel 310 or third-party models, Azima integrates it all to deliver actionable insights. This flexibility means that Azima becomes a natural part of your maintenance strategy — fitting into your processes without interruption and amplifying your ability to act on critical insights.
Tying It All Together: From Insights to Outcomes
Asset criticality analysis and Azima’s predictive maintenance tools are two sides of the same coin. By pinpointing the machines that matter most, teams can direct monitoring efforts where they’ll have the greatest impact. Azima then turns this focus into action, identifying early warning signs, diagnosing faults, and prioritizing risks long before failures occur.
These insights don’t stand alone — they feed into broader processes like work management and reliability engineering. By connecting diagnostics with actionable plans, teams can streamline workflows, reduce recurring failures, and refine asset strategies. This integration transforms maintenance from a reactive task into a proactive force that supports operational resilience and long-term success.
Focus and foresight turn maintenance into something rare: a system you can trust.
This article is based on an Xcelerate 24 session on asset criticality presented by Steve Hudson, director of professional services at Fluke Reliability, and Blake A. Baca, owner and asset management coach at BDB Solutions, LLC.